



NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など
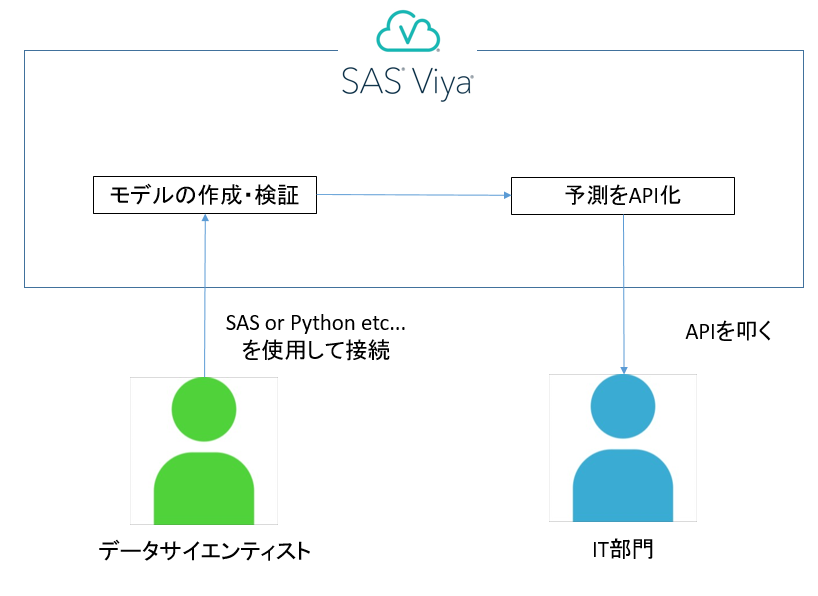





SAS Viyaで作成した機械学習モデルをAPI化して予測する
お久しぶりです。
弊社にもようやくSAS Model Managerが来ましたので、それを使用した
分析環境の構築を紹介できればと思います。
ModelOpsの概念
まずはじめに、SAS社が掲げているModelOpsについて紹介します。
https://www.sas.com/ja_jp/solutions/operationalizing-analytics/modelops-approach.html
>ModelOpsは、モデル関連の工程(開発⇒検証⇒テスト⇒業務実装)の進捗ペースを最大限に高めながら、
>質の高い結果も確保することにフォーカスします
このモデル開発→業務実装を迅速にする、というのがキーワードだと思っています。
データサイエンティストには分析結果、予測結果をIT部門に使用してもらえるような開発が求められることが多々あり、
実装のための知識が足りなかったりすると、そこで時間がとられてしまうことが多々あります。
かといって、IT部門が実装を行おうとすると、正確なモデルの理解が必要となり、
やはり時間がかかってしまいます。
これを解決してくれるのが、SAS ViyaのModel Managerです。
Model Managerは作成したモデルを管理し、必要に応じてモデルをパブリッシュします。
パブリッシュされたモデルはAPIを使用して予測することができます。
Model ManagerはGUIでもCUIでも使用することができ、簡単な操作・コードで実行することができます。
もし予測をAPI化してしまえば、多くのプログラム言語・アプリケーションから実行することができ、
さらにAPIを使用する人はモデルの詳細は知る必要はありませんので、
データサイエンティストはIT部門への引継ぎがとても楽になります。
今回は以下の流れを想定して、分析環境を構築していきます。
以下からは、実際にpythonで予測APIを作成してみます。
モデルの作成
前回ブログに書いた内容とほぼ同じです。
フォルダの構成やコードの詳細は下記を参照してください。
https://www.n-insight.co.jp/niblog/20191202-1449/
# cas serverへ接続
import swat
import pandas as pd
# 接続
sess = swat.CAS(<hostname>,<port>,username=<username>,password=<password>)
sess.serverstatus()
# 変数名「default.payment.next.month」を「default」に変更
df = pd.read_csv("./data/UCI_Credit_Card.csv")
df = df.rename(columns={"default.payment.next.month":"default"})
df.to_csv("./data/UCI_Credit_Card_change.csv",index=False)
# dataをアップロード
castbl = sess.upload_file(data='./data/UCI_Credit_Card_change.csv',
casout=dict(name='CreditCard',
caslib='casuser', replace=True))
#アクションセットのロード
sess.loadactionset("decisionTree")
sess.loadactionset("sampling")
# データの分割
sess.sampling.stratified(
table={"name":"CREDITCARD", "groupBy":"default"},
output={"casOut":{"name":"CREDITCARD_part", "replace":True}, "copyVars":"ALL"},
samppct=70,
partind=True
)
sess.CASTable("CREDITCARD_part").head(5)
# 勾配ブースティング学習(savestateを入れること!)
sess.decisionTree.gbtreeTrain(
table={
"name":"CREDITCARD_part",
"where":"strip(put(_partind_, best.))='1'"
},
inputs=["PAY_0", "PAY_2","LIMIT_BAL", "AGE"],
target="default",
nTree=100,
nBins=20,
maxLevel=6,
varImp=True,
missing="USEINSEARCH",
casOut={"name":"gb_model", "replace":True},
savestate='gb_model_astore'
)モデルの登録・パブリッシュ
次からが本題になります。
モデルの登録・パブリッシュを行うには
「sasctl」というパッケージを使用します。
以下では、Model Managerを使用してモデルを登録し、
MicroAnaliticsService(MAS)にパブリッシュしています。
import sasctl
from sasctl.tasks import register_model,publish_model
# データの取得
astore = sess.CASTable("gb_model_astore")
with sasctl.Session("<hostname>",username="<username>",password="<password>",verify_ssl=False) as ctl_sess:
#モデルの登録
model = register_model(astore, 'testmodel', project='MyProject',force=True)
#モデルのパブリッシュ(パブリッシュ先はMicroAnaliticsService)
module = publish_model(model, 'maslocal',replace=True)予測APIを構築 ~clientの登録~
APIを使用するには、以下の手順でアクセストークンを取得する必要があります。
https://developer.sas.com/reference/auth/
(以下のコードはSAS ViyaがインストールされているVMで実行)
cd /opt/sas/viya/config/etc/SASSecurityCertificateFramework/tokens/consul/default
sudo cat client.tokenimport requests
import ast
url = "https:///SASLogon/oauth/clients/consul?callback=false&serviceId=app"
values = {"X-Consul-Token":"<client_token>"}
resp = requests.post(url,headers=values, verify=False)
res = ast.literal_eval(resp.text) (<client_id>,<client_password>には任意の値を入れてください。)
import json
url = "https://<hostname>/SASLogon/oauth/clients"
headers = {"Content-Type":"application/json","Authorization":"Bearer {}".format(res["access_token"])}
data = {"client_id": "<client_id>",
"client_secret": "<client_password>",
"scope": ["openid"],
"authorized_grant_types": ["password"],
"access_token_validity": 43199
}
client_resp = requests.post(url,json.dumps(data),headers=headers, verify=False)予測APIを構築 ~予測API用のアクセストークンの取得~
次は予測API用のアクセストークンの取得です。
import requests
username=<username>
password=<userpassword>
url = "https://<client_id>:<client_password>@<hostname>/SASLogon/oauth/token"
headers = {"Content-Type":"application/x-www-form-urlencoded"}
data = "grant_type=password&username={}&password={}".format(username,password)
token_resp = requests.post(url,data,headers=headers, verify=False)予測APIを使用
実際に予測APIを使ってみましょう。
入力データは以下になるように調整します。
{
"inputs":
[{"name": "<column-name>", "value": <value>},
…,
{"name": "<column-name>", "value": <value>}]
}credit_df = pd.read_csv('./data/UCI_Credit_Card_change.csv')
dicts = credit_df.iloc[0].to_dict()
input_data = [{"name":k,"value":v} for k,v in dicts.items()]
input_data = {"inputs":input_data}
# 目的変数「default」にはダミーとして0を代入
input_data["inputs"][-1]["value"]=0
input_data = json.dumps(input_data)
print(input_data)'{"inputs": [{"name": "ID", "value": 1.0}, {"name": "LIMIT_BAL", "value": 20000.0}, {"name": "SEX", "value": 2.0}, {"name": "EDUCATION", "value": 2.0}, {"name": "MARRIAGE", "value": 1.0}, {"name": "AGE", "value": 24.0}, {"name": "PAY_0", "value": 2.0}, {"name": "PAY_2", "value": 2.0}, {"name": "PAY_3", "value": -1.0}, {"name": "PAY_4", "value": -1.0}, {"name": "PAY_5", "value": -2.0}, {"name": "PAY_6", "value": -2.0}, {"name": "BILL_AMT1", "value": 3913.0}, {"name": "BILL_AMT2", "value": 3102.0}, {"name": "BILL_AMT3", "value": 689.0}, {"name": "BILL_AMT4", "value": 0.0}, {"name": "BILL_AMT5", "value": 0.0}, {"name": "BILL_AMT6", "value": 0.0}, {"name": "PAY_AMT1", "value": 0.0}, {"name": "PAY_AMT2", "value": 689.0}, {"name": "PAY_AMT3", "value": 0.0}, {"name": "PAY_AMT4", "value": 0.0}, {"name": "PAY_AMT5", "value": 0.0}, {"name": "PAY_AMT6", "value": 0.0}, {"name": "default", "value": 0}]}'import requests
url = r'https://<hostname>/microanalyticScore/modules/testmodel/steps/score'
bearer_token = ast.literal_eval(token_resp.text)["access_token"]
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer {}'.format(bearer_token)
}
response = requests.post(url,input_data, headers=headers, verify=False)
print(response.text){
"links":[],
"version":2,
"moduleId":"testmodel",
"stepId":"score",
"executionState":"completed",
"outputs":[
{"name":"P_default","value":0.7382448276157634},
{"name":"_WARN_","value":null}
]
}APIを使用しているので、様々なアプリケーションから予測ができそうです。
参考:エラーハンドリング
パブリッシュの際、以下のエラーが起こる可能性があります。
RuntimeError: Failed to publish model 'testmodel': ERROR==={"errorCode":0,"message":"Cannot create, update or load
the module \"testmodel\". The file \"file:///models/astores/viya/***\"
is not accessible from this server.","links":[],"version":2,"httpStatusCode":0}https://go.documentation.sas.com/?cdcId=calcdc&cdcVersion=3.5&docsetId=calmodels&docsetTarget=n10916nn7yro46n119nev9sb912c.htm&locale=en
まとめ
今回はMASにモデルをパブリッシュし、APIを使用した予測を行いました。
これにより、機械学習によるwebアプリの実装等が可能になったり、BIツール等で予測結果の可視化もできたりしそうですね!
また、作成したモデルの予測結果の算出方法については、APIのほかにも、アクションセットを使用してCASからバッチ予測をする方法もあります。SASやPythonから大規模なデータを処理したいのであればバッチ予測のほうが効率が良いです。それも後々ブログで書けていけたらなと思います。(以下はバッチ/API予測の使い方がまとまっている参考URLです)
https://pyviya.com/scoring-models




コメント