



NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など





JupyterLabでPythonのsaspyパッケージを使ってみた
JupyterLabとは
JupyterLabとはJupyter NotebookをベースとしたWeb上のIDEです。
SASのUniversity EditionのInformation CenterでSAS Studioの下にリンクがあります。

JupyterLabに入ると下記のような表示になるので、「Notebook」の「Python 3」を選びます。

下記のようにPythonが対話型で実行できるようになります。

CSVファイルからDataFrameオブジェクトを生成する
まずはsaspyとpandasのパッケージを読み込みます。
import saspy
import pandas as pd なお、標準では入力フィールド内でShift+Enterで実行します。
なお、標準では入力フィールド内でShift+Enterで実行します。
入力フィールド内で改行する場合はEnterです。
SASデータセットにする入力ファイルをフォルダ内にアップロードします。
(今回は、SASのSASHELPライブラリに格納されているBaseballをCSVファイルにしたものを使用します)

pandasのread_csvメソッドでアップロードしたCSVファイルを読み込み、DataFrameオブジェクトを生成します。
df = pd.read_csv('baseball.csv')
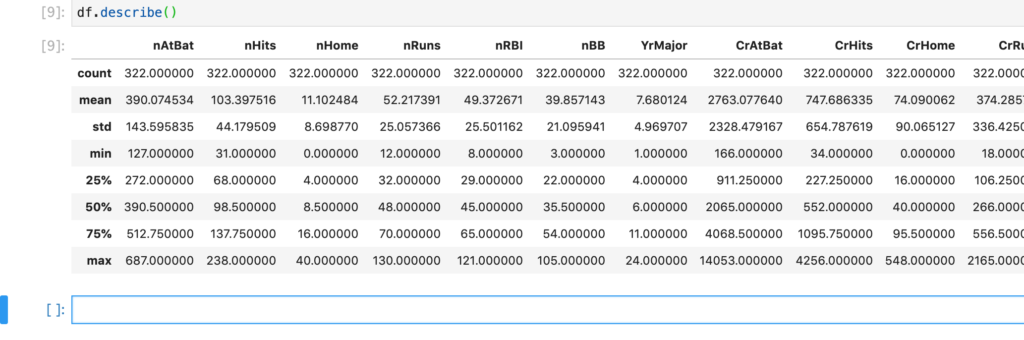
describeメソッドで見ると下記のようになります。
SASDataオブジェクトを生成する
次に、saspyパッケージのSASsessionオブジェクトを生成します。
sas = saspy.SASsession()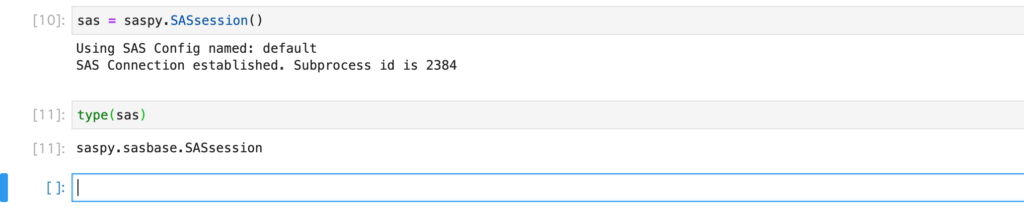
sasで、SASsessionオブジェクトの中身が見られます。
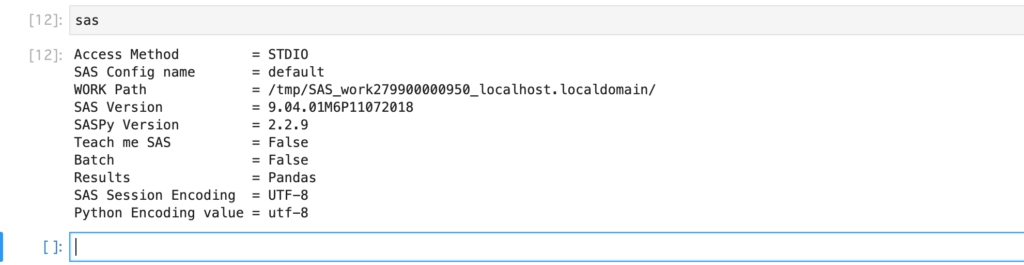
次に、df2sdメソッドでCSVファイルから生成したDataFrameオブジェクトからSASdataオブジェクトを生成します。
baseball = sas.df2sd(df, 'baseball')
これでbaseballというSASdataオブジェクトに対しての様々なメソッドが使用できます。
SASdataオブジェクトのメソッドを使ってみる
SASdataオブジェクトのメソッドをいくつか試してみます。
describeメソッド
SASデータセットの要約統計を表示します。
baseball.describe()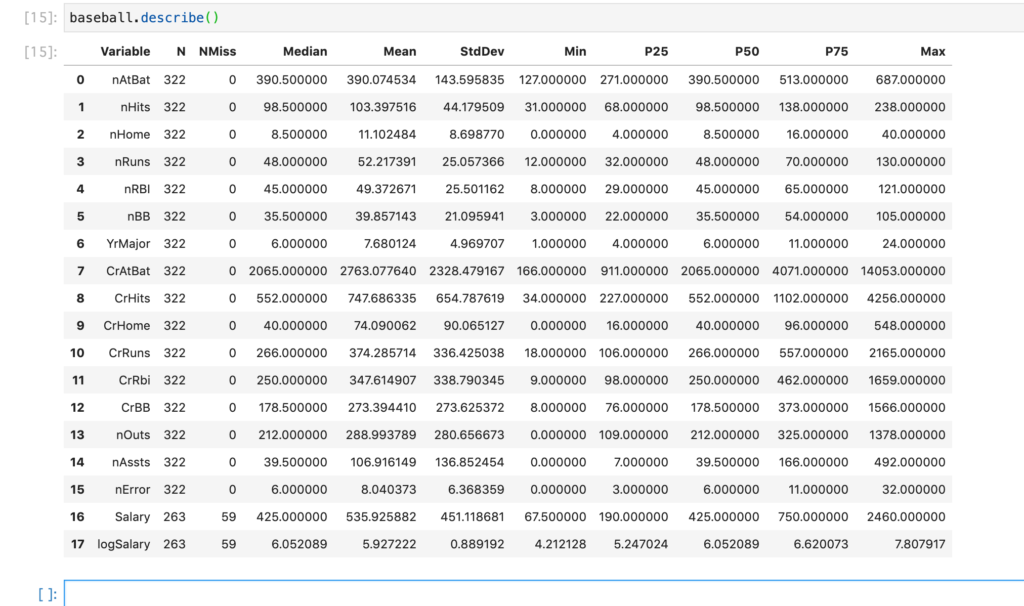
headメソッド
SASデータセットの先頭5オブザベーションを表示します。
baseball.head()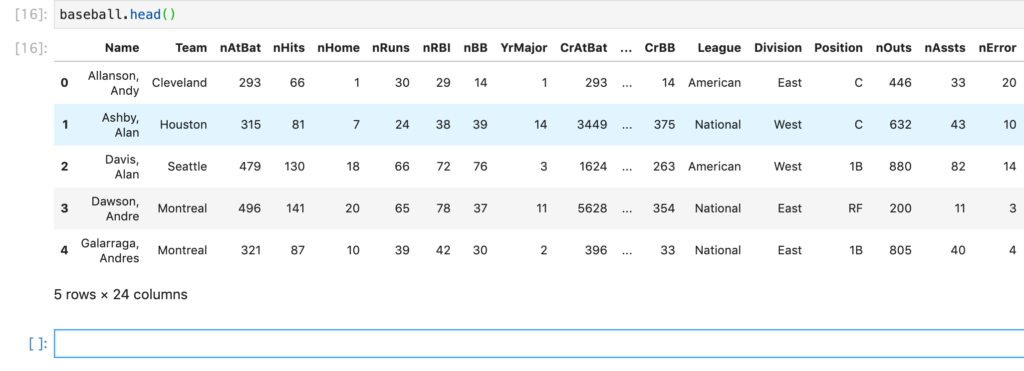
標準では5オブザベーションですが、下記のように引数を渡すこともできます。
# 先頭2オブザベーションを表示
baseball.head(obs=2)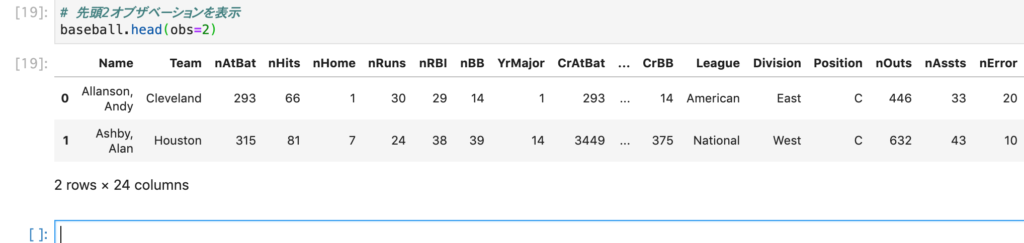
tailメソッドを使えばSASデータセットの最終オブザベーションからの表示もできます。
barメソッド
引数に文字変数を指定し、その度数を棒グラフで返します。
ここでは変数Teamごとの度数を表示します。
baseball.bar('Team')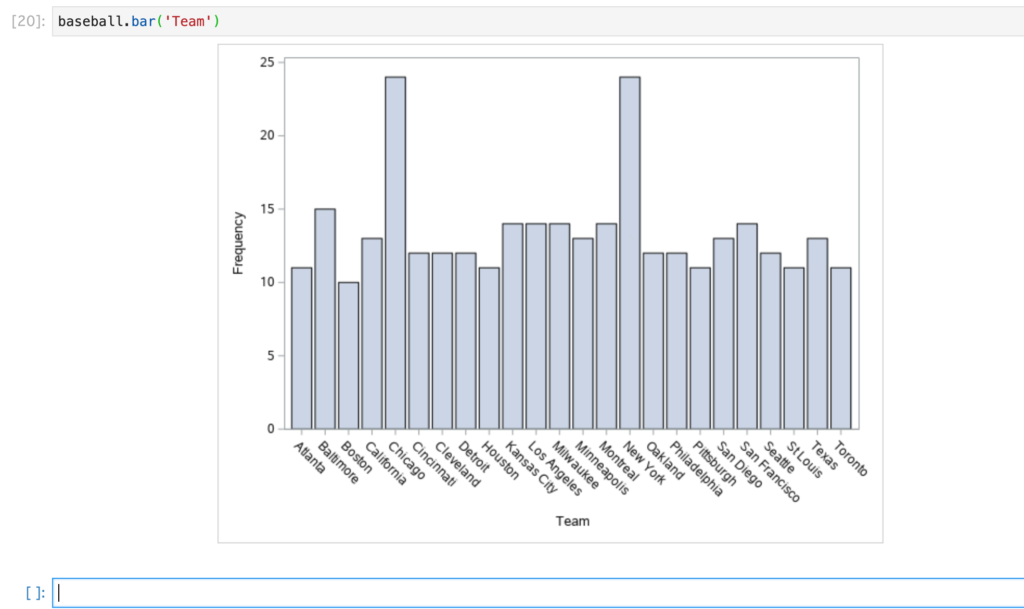
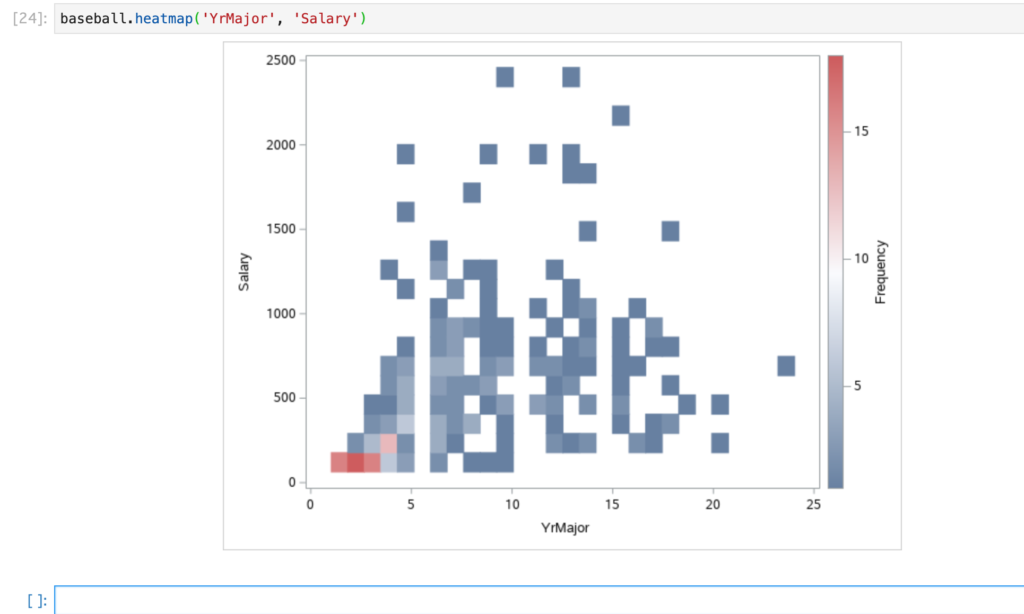
heatmapメソッド
引数に2つの数値変数を指定し、ヒートマップを作成します。
ここではYrMajor(メジャー在籍年数)とSalary(年俸$)を指定します。
baseball.heatmap('YrMajor', 'Salary')
ちなみに、下記のようにSASsessionオブジェクトのteach_me_SASメソッドを使用すると、
SASのプロシジャの中身を表示することもできます。
sas.teach_me_SAS(True)
baseball.heatmap('YrMajor', 'Salary')
sas.teach_me_SAS(False)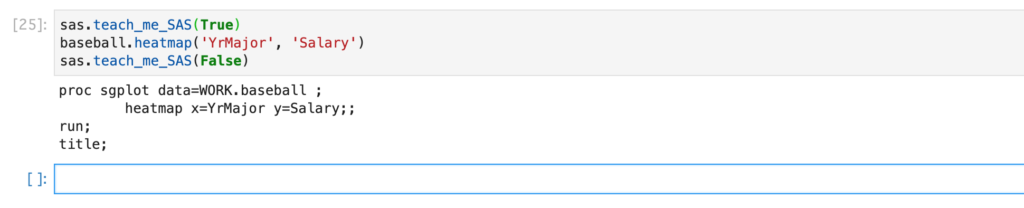
以上、Pythonのsaspyパッケージの使い方を簡単に説明しました。
下記の公式ドキュメントにAPIリファレンス等もありますので、参考にしてください。
https://sassoftware.github.io/saspy/index.html





コメント