






NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など





SASで決定木分析
決定木とは
決定木とは機械学習の教師あり学習の1つで、特徴量をif-else形式で繰り返し分割して予測を行うシンプルなモデルです。
決定木は目的変数が離散でも連続でも使用できます。離散の場合は分類木、連続の場合は回帰木と呼ばれます。(一般的に決定木と呼んだ場合は分類木のことを指すことが多いです。)
SASでは双方ともに実行可能です。今回は分類木について掘り下げていきます。
決定木のOUTPUT
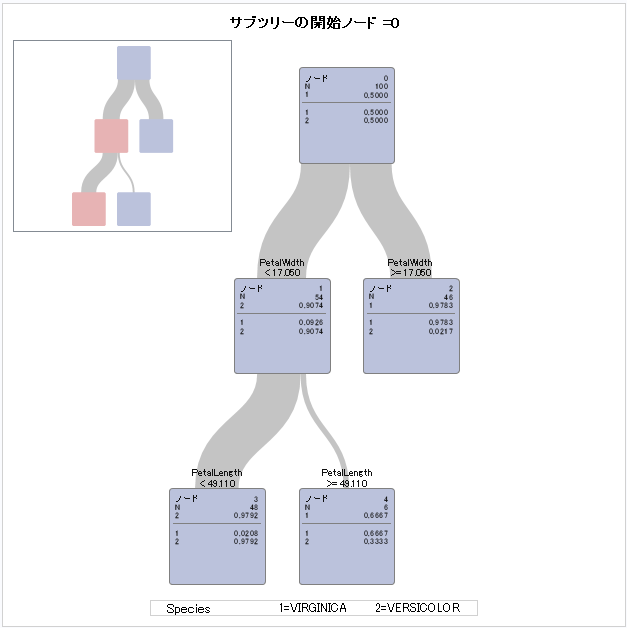
では、SASHELP.IRISのSpecies(VIRGINICA or VERSICOLOR)を決定木を使用して予測してみましょう。2値分類です。
ods graphics on ;
proc hpsplit data=sashelp.iris(where=(species ^= "Setosa")) ;
target species ;
input SepalLength -- PetalWidth;
run ;この決定木から、以下のことが分かります。
決定木のメリット・デメリット
決定木のメリット
決定木のデメリット
決定木は、そこそこの精度で、変数に制約が少なく、説明性に優れたモデルと考えてよいでしょう。
決定木の分割方法
まずは決定木はどのように分割しているかを知りましょう。
決定木は、各特徴量を色々な値で分割してみて、分割後にできるだけ0と1を分離できる分割を探します。(ただ、連続値を一つずつ分割していくのは時間がかかりすぎるので、まとまりに分けて分割します。SASではデフォルトで100個のまとまりを作成します。)
その際、0と1がどれだけ分かれたかを表す指標が必要になります。ジニ係数とエントロピーがあり、どちらかを選択します。SASではデフォルトではエントロピーを使用しています。
決定木の木の深さと過学習
決定木は深くすればするほど訓練データの当てはまりは良くなります。
では、できるだけ深くすればよいのでしょうか。答えはNOです。
木が深くなりすぎると今手元にある訓練データの当てはまりばかりよくなって、
実際の予測ではうまくいかない場合があります。これを過学習と呼びます。
(以下の例では、サイズが1~3のノードが多くなり、ほぼ個別に予測している形になってしまっています。)
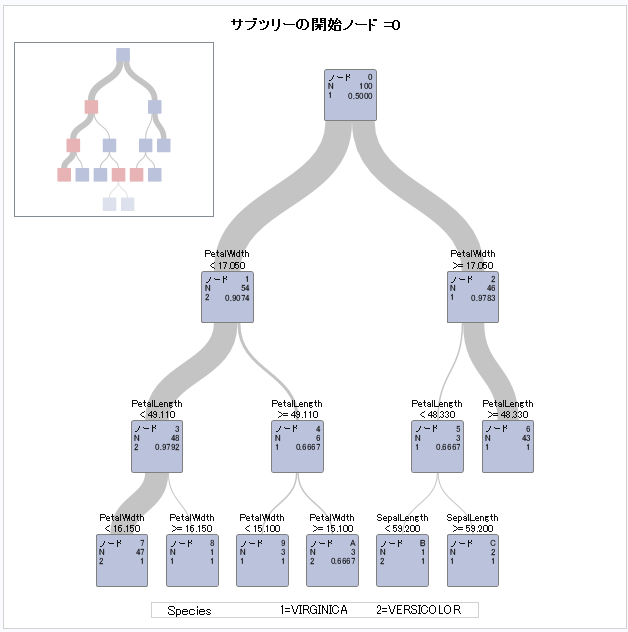
決定木では過学習が起きやすいため、SASでは過学習を抑えるために様々なパラメータが用意してあります。 今回はその一部を紹介します。
決定木の精度評価とHold Out法
機械学習全般にいえることですが、精度を評価するときに学習に使用したデータを使用することは、カンニングであり、正しく評価できません。特に過学習しやすい決定木では正しい評価が必要になります。その対策として、最初に学習用と評価用にデータを分割し、学習用データのみで決定木を作成し、評価用データを用いて評価を算出します。これをHold Out法と呼びます。一般的には7:3から8:2あたりの分割がいいとされています。
SASのhpsplitではpartitionステートメントを用いて簡単に実装できます。
SASの決定木の構文
SASで決定木を回すための構文・主要なパラメータを紹介します。
詳しくはSASのドキュメントを参照してください。
SASのドキュメント
コードのSyntax(Hpsplit プロシジャ)
proc hpsplit data = (データセット名)
intervalbins = (閾値を定めるための分割数、デフォルト値=100)
maxdepth = (木の最大の深さ、デフォルト値=10)
leafsize = (葉の最小件数、デフォルト値=1)
maxbranch = (1分岐あたりの最大の枝の数)
;
input (説明変数) ;
target (ターゲット変数) ;
criterion (不純度の指標) ;
partition (入力データを学習データと検証データに分割する方法) ;
prune (剪定方法) ;
code file = (ファイル参照名またはフルパス); ← スコアリングに使用できるコードを出力
rules file = (ファイル参照名またはフルパス); ← 最終的なツリーの葉を出力
score out = (データセット名); ← 入力データにスコアリングしたデータを出力
id (変数) ; ← 入力データにスコアリングしたデータに残す変数を指定
output
importance = (データセット名) ← 各変数の重要度のデータセットを出力
nodestats = (データセット名) ← 最終的なツリーの説明
;
run;SASで実際に決定木分析
実際に上記を踏まえて決定木で分析してみます。
ハイパーパラメータであるmaxdepthやcriterion、prune等を変えながら分析してみましょう。
/*train*/
proc hpsplit data=sashelp.iris(where=(species ^= "Setosa")) maxdepth=3;
target species ;
input SepalLength -- PetalWidth ;
criterion gini ;
prune c45 ;
partition fraction(validate = 0.2)/ SEED = 1;/*評価用データで精度評価*/
code file="your file path";/*予測する際のコードを生成*/
run ;
/*predict*/
data work.test_predict;
set sashelp.iris(where=(species ^= "Setosa"));
%include "your file path";
run;IRISデータで剪定を実施した結果、深さ2の木が生成されていますね。
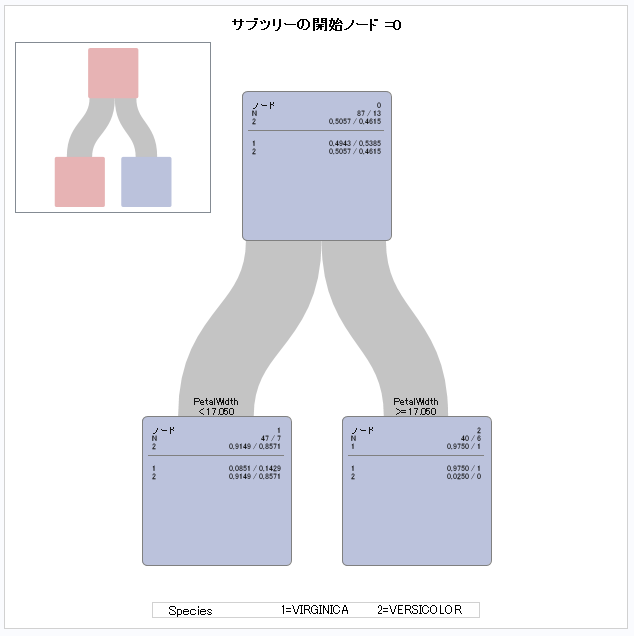
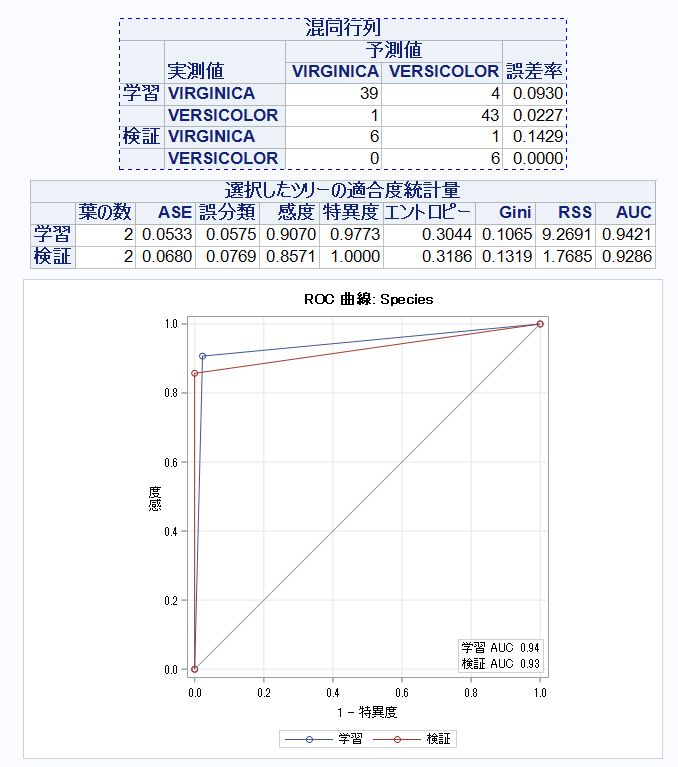
精度は検証用の数値を見るようにしましょう。
データ数は少ないですが、精度的にはかなり高いですね。
まとめ
今回はSASでの決定木を紹介しました。
決定木はシンプルで分かりやすく、適切に使用すれば
とても有用なモデルになります。
また、今回は分類木の紹介でしたが、hpsplitでは回帰木も同様の構文で書けますので、
興味ある方は調べてみてください。





コメント