



NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など






SAS Viyaで画像分類
近年ディープラーニングによって画像認識技術が発展し、
さらに日に日に簡単に利用できるようになっています。
今回は、画像分類をSAS Viyaを利用して実装していきます。
インターフェースはPythonを使用します。
画像の準備
まず画像を準備します。今回はcifar10を使用します。
cifar10は10クラスのラベルが付いた画像データで、
train_dataは50000画像あります。
画像は以下から入手することができます。
https://www.cs.toronto.edu/~kriz/cifar.html

では、cifar10を使用できる状態にしましょう。
まずは必要なモジュールをインポートします。
import os
import sys
import urllib.request
import tarfile
import numpy as np
from PIL import Image
import cv2
import matplotlib.pyplot as plt
from tqdm import tqdm_notebookdirpath = "your directory"
labelDict = {
0: "airplane",
1: "automobile",
2: "bird",
3: "cat",
4: "deer",
5: "dog",
6: "frog",
7: "horse",
8: "ship",
9: "truck"
}url = 'http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz'
filename = url.split('/')[-1]
filepath = os.path.join(dirpath, filename)
def _progress(cnt, chunk, total):
now = cnt * chunk
if(now > total): now = total
sys.stdout.write('\rdownloading {} {} / {} ({:.1%})'.format(filename, now, total, now/total))
sys.stdout.flush()
urllib.request.urlretrieve(url, filepath, _progress)
tarfile.open(filepath, 'r:gz').extractall(dirpath)# フォルダの作成
for i in range(0,10,1):
os.makedirs(os.path.join(dirpath,"traincifar",labelDict[i]), exist_ok=True)
# train_dataの作成
for nbin in range(1,6,1):
path = dirpath+"/cifar-10-batches-bin/data_batch_{0}.bin".format(nbin)
label_size = 1
img_size = 32 * 32 * 3
data_size = label_size + img_size
dnum = 10000
with open(path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, count=data_size*dnum)
for i in tqdm_notebook(range(dnum)):
start = i * data_size
label = data[start]
label = labelDict[label]
img_arr = data[start + 1 : start + data_size]
img = np.array(img_arr.reshape(3, 32, 32).transpose(1,2,0), dtype=np.uint8)
name = "{0}_train_{1}_{2}.png".format(label,nbin,i)
Image.fromarray(img).save(dirpath+"/traincifar/{0}/{1}".format(label,name))├─cifar-10-batches-bin
└─traincifar
├─airplane
├─automobile
├─bird
├─cat
├─deer
├─dog
├─frog
├─horse
├─ship
└─truckSAS Viyaで画像を読み込む
画像が準備できたら、SAS Viyaに画像を取りこみましょう。
その前に、もしPythonとSAS Viyaの環境が違うのであれば、
cifar10の画像はPythonを実行している環境に入っているため、
必ずSAS Viyaの環境に移してください。
さて、画像の読み込みに戻ります。
まずは必要なswatやdlpyモジュールを読み込みます。
import swat
from dlpy.network import *
from dlpy.layers import *
from dlpy.model import *
from dlpy.images import ImageTable
from dlpy.sequential import Sequential
from dlpy.utils import display_object_detections, plot_anchors
from configparser import ConfigParserアクセス方法(setting.iniの構成方法等)は、
前回のブログの「Python から SAS Viyaに接続する」と同様ですので、
そちらと合わせてご覧ください。
config = ConfigParser()
config.read('./config/setting.ini')
swat.options.cas.debug.responses = False
conn = swat.CAS(config['DEFAULT']['URL'],8080,config['DEFAULT']['ID'], config['DEFAULT']['PASSWORD'])
conn.serverstatus()conn.loadactionset("image")
conn.loadactionset("deeplearn")今回はtrainのみを使用します。
from dlpy.splitting import two_way_split
traindata = conn.image.loadImages(
casout={'name':'cifar10train', 'replace':True},
path=r'cifar10/traincifar',
labellevels=1,
recurse=True)ImageTableを使用することにより、画像処理を行うことができます。
さらに、trainとvalidに分割します。
traindata = ImageTable.from_table(conn.CASTable("cifar10train"))
# trainとvalidに分割
traindata, validdata = two_way_split(traindata, test_rate=20, seed=12345)traindata.show()
32×32の画像なので荒いですが、何が映っているかは分かります。
この画像を入力として、何が映っているかを予測することを目指します。
SAS Viyaでモデル構築、トレーニング
今回はConv→Conv→Pool→Conv→Conv→Pool→dense→softmaxという
シンプルなCNNを構築します。
CNNの具体的な説明は長くなるので省きますが、
簡単に言うと、小さいフィルターを移動させて特徴量を作成し、
それをもとにラベルを予測するディープラーニングの手法の一つです。
物体が映っている場所によらずに特徴を探すことができます。
以下のブログが分かりやすかったので詳しくは参考にしてください。
https://blogs.sas.com/content/sasjapan/2017/12/13/sasviya-cnn/from dlpy.layers import *
model1 = Sequential(conn, model_table='Simple_CNN')
model1.add(InputLayer(3, 32, 32))
model1.add(Conv2d(n_filters = 16,
width = 3,
height = 3,
act='relu'))
model1.add(BN())
model1.add(Conv2d(n_filters = 16,
width = 3,
height = 3,
act='relu'))
model1.add(BN())
model1.add(Pooling(width = 2,
height = 2))
model1.add(Conv2d(n_filters = 32,
width = 3,
height = 3,
act='relu'))
model1.add(BN())
model1.add(Conv2d(n_filters = 32,
width = 3,
height = 3,
act='relu'))
model1.add(BN())
model1.add(Pooling(width = 2,
height = 2))
model1.add(Dense(128))
model1.add(OutputLayer(act='softmax', n=10))
mini_batch_sizeやmax_epochsは実行時間やマシンスペックによって変えることをお勧めします。optimizer=Optimizer(algorithm=dict(method='ADAM',beta1=0.9, beta2=0.999,learningRate=0.01),
mini_batch_size=64,
max_epochs=50,
log_level=0)
複雑なモデルはコードを見ただけでは分からないので、この機能はありがたいですね。
(以下の出力結果は一部抜粋しております。)model1.plot_network()
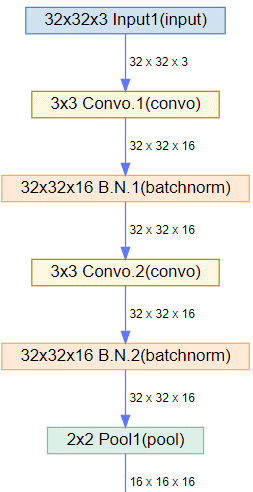
次にトレーニングを行います。
今回はCPUで演算していますが、もしGPUが使用できるのであれば、ここでgpuの引数を加えてください。
model1.fit(data=traindata,
valid_table=validdata,
optimizer=optimizer,
seed=100,
log_level=2)結果の可視化と予測
学習をしたら、まずは正しく学習されているかを確認する必要があります。
まずはtraindataのlossと正解率を見てみましょう。
model1.plot_training_history()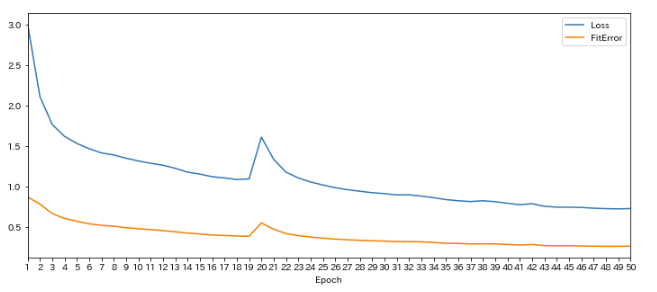
一部lossが上がっていますが、全体としてはlossが下がっていますね。
validdataと合わせて、lossと正解率を見てみます。
opeHis = model1.training_history
epochHis = opeHis["Epoch"]
trainLoss = opeHis["Loss"]
trainError = opeHis["FitError"]
valLoss = opeHis["ValidLoss"]
valError = opeHis["ValidError"]
fig, ax1 = plt.subplots(figsize=(12,8))
ax1.plot(epochHis, trainLoss, "b:", label="trainLoss")
ax1.plot(epochHis, valLoss, "r:", label="valLoss")
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.legend(loc="upper center", bbox_to_anchor=(0.5,-0.1), ncol=2)
ax2 = ax1.twinx()
ax2.plot(epochHis, 1-trainError, "b--", label="trainAcc")
ax2.plot(epochHis, 1-valError, "r--", label="valAcc")
ax2.set_ylabel("Accuracy")
ax2.legend(loc="upper center", bbox_to_anchor=(0.5,-0.2), ncol=2)
plt.title("CNN Training")
plt.grid(True)
plt.rcParams["font.size"] = 20
plt.ylim([0,1])
plt.show()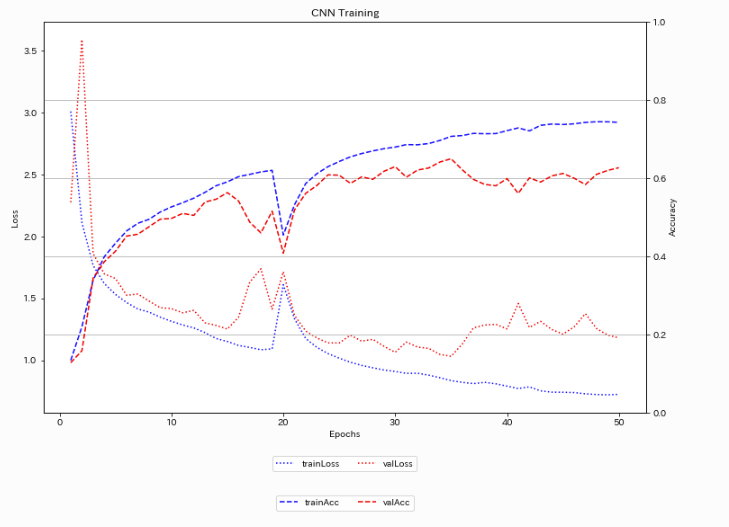
正解率も上昇傾向にありますね。
結果を確認したので、予測を行いましょう。
validdataに対して、ラベルを予測します。
model1.evaluate(data=validdata)次に、正解ラベルと不正解ラベルの予測確率を確認します。
画像と並べて確率を出してくれるのでとても見やすいですね!
# 正解ラベルの予測
model1.plot_evaluate_res(img_type='C', randomize=True, n_images=2)# 不正解ラベルの予測
model1.plot_evaluate_res(img_type='M', randomize=True, n_images=2)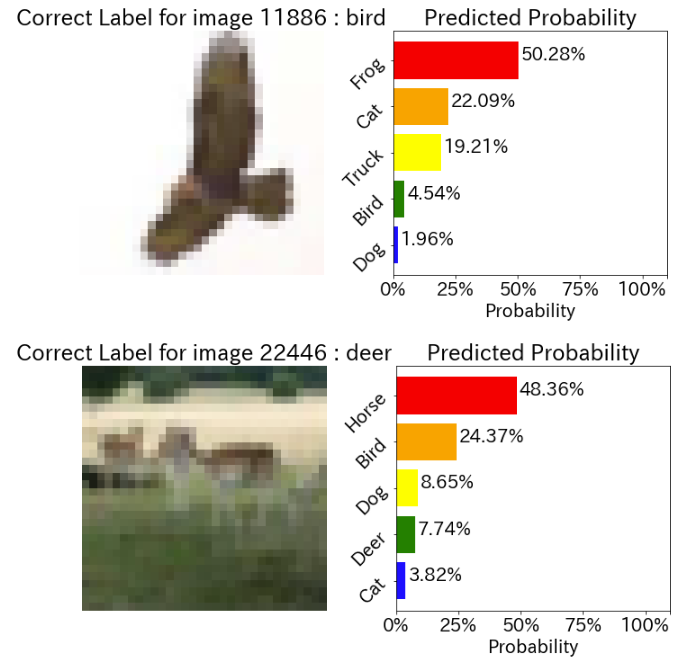
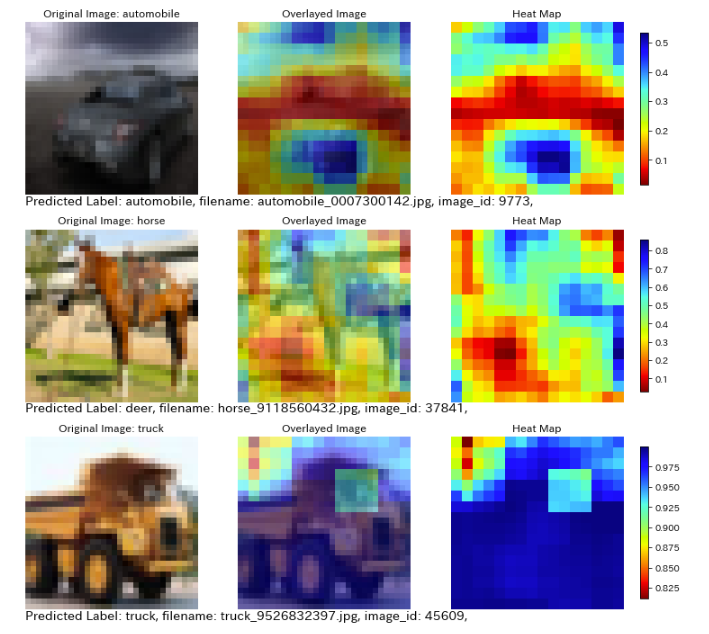
またこれもすごいのですが、CNNの中間層を取り出して、
CNNがどの部分が分類において重要かの可視化を行ってくれます。
なお、値が高い(=青い)部分を重要としているらしいです。
(参考:https://arxiv.org/pdf/1311.2901.pdf)
予測した結果を保存しましょう。
予測したテーブルはmodel1.valid_res_tblに入っています。
model1.valid_res_tbl[["_filename_0","I__label_"]].to_csv(r"your csv path")まとめ
今回はSAS Viyaで画像分類を行いました。
SAS Viyaはモデルや結果の可視化が綺麗で、わかりやすいですね。
今回は単純なCNNの紹介でしたが、VGGやResNetを用いた転移学習、
Faster RCNNやYOLOなどのオブジェクト認識も紹介していきたいと思います。
参考
1. https://blogs.sas.com/content/sasjapan/2017/12/13/sasviya-cnn/
2. https://github.com/sassoftware/python-dlpy
3. https://blogs.sas.com/content/sasjapan/2018/05/21/sas-viya-dl_ml_interpretation/





コメント